
Getting Azure Certified: What I Learned About Cloud Computing, Self-Learning, and Big Data More Broadly

As a data and software engineer, I’ve always been uneasy with my lack of experience in cloud computing. Most of my work has been with open-source tools and self-hosted environments. A few months ago, I decided to change that by getting certified in a cloud platform to gain hands-on experience with PaaS technologies

I chose Microsoft Azure, specifically the Data Engineer DP-203 certification, because I found it to have the most robust options for data integration of any platform. Azure has tools for real-time event processing, data lakes, warehouse storage, workflow orchestration, and big data processing. It also helped that Microsoft offered a discount on the exam if you completed their free online training, which I did.
After a few months of learning and studying, I took the exam and passed. It was a very rewarding and educational experience, and significantly advanced my understanding of cloud-based data engineering. I want to share what I learned about Azure, the exam itself, and cloud data engineering in practice.
Azure Explained
Microsoft Azure is a cloud computing platform that provides an ecosystem for building scalable data architectures and backend processes. It has a comprehensive toolkit for ingesting, storing, transforming, and analysing your data. It’s a great option for companies that don’t have the resources to self-host on their own servers, so they build everything on a cloud platform, allowing them to focus less on hardware costs and more on applying their business processes. Hardware is both reliable and scalable, so if your business experiences massive growth, you know that everything will remain reliably active.

There’s a lot of options for handling your data, from traditional ETL to more modern ELT pipelines, as well as automating repeatable workflows. There’s functionality for scaling pipelines to handle big data with Synapse and Databricks, optimizing costs by using on-demand and serverless computing, and implementing security frameworks for governance and comliance. You can also integrate your own open-source solutions if that’s what you prefer.
What the Exam Covers
The DP-203 exam focuses on four big domains: storage, processing, security, and monitoring/optimization.
1. Data Storage
Azure Data Lake Storage (ADLS) Gen2 & Blob Storage for raw and unstructured data.
Cosmos DB for NoSQL document storage.
Azure SQL Database for OLTP workloads.
External tables in Synapse Analytics and Delta Lake tables in Databricks.
Partitioning, compression, and indexing strategies for performance optimization.
2. Data Processing
Building data ingestion pipelines with Data Factory, Databricks, and Synapse Analytics.
Implementing ETL and ELT workflows.
Using PolyBase for efficient data movement into Synapse Analytics.
Leveraging Apache Spark on Databricks for large-scale transformations.
3. Data Security
Managing role-based access control (RBAC) for users, groups, and services.
Implementing encryption at rest and in transit.
Controlling network access through private endpoints and firewall rules.
Securing credentials with Azure Key Vault.
4. Data Monitoring and Optimization
Configuring Azure Monitor and Log Analytics for performance tracking.
Implementing cost optimization strategies.
Debugging and optimizing failed jobs for efficiency.
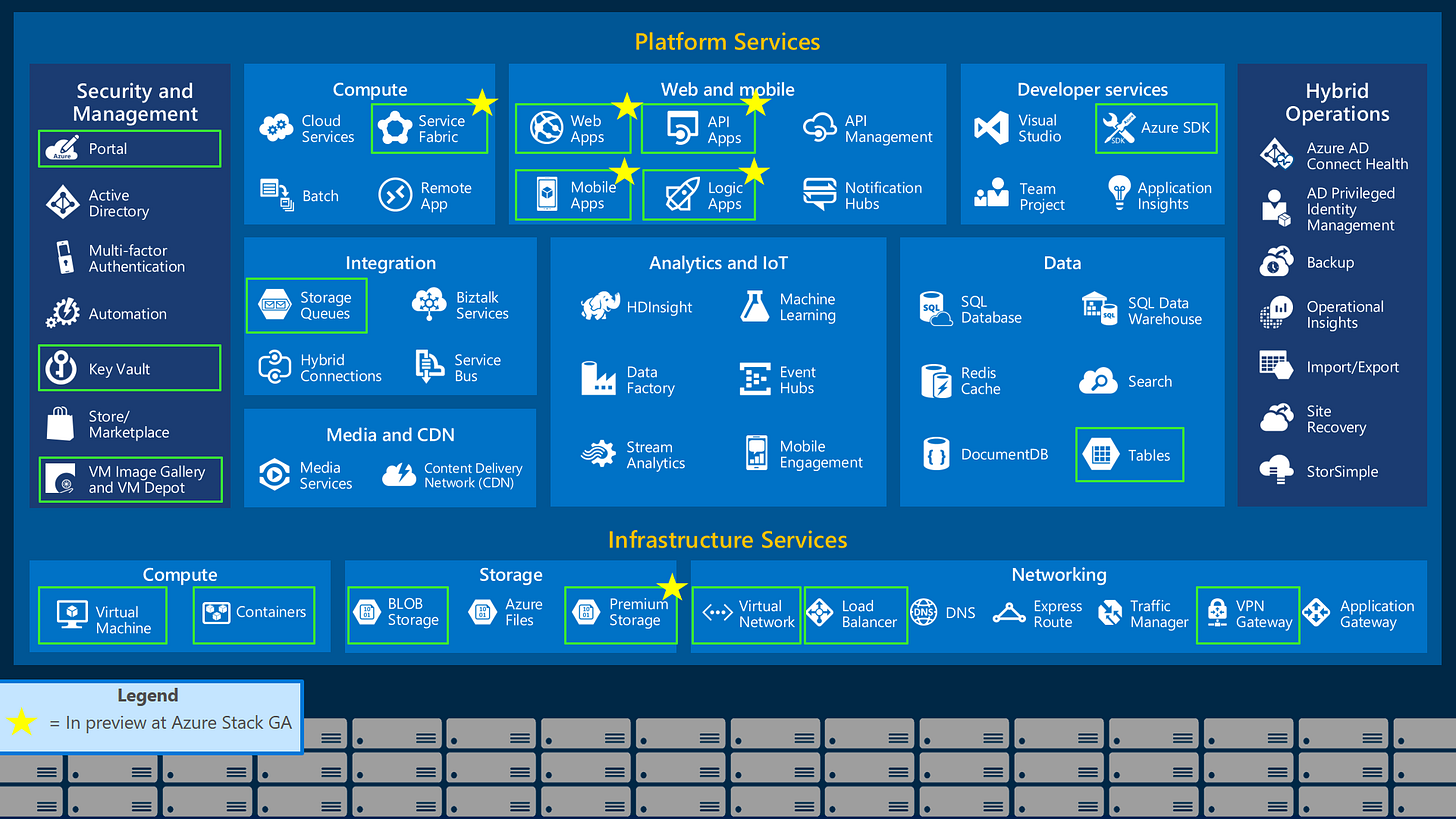
Azure at a high level
How I Studied
The most valuable learning resources were Microsoft Learn and hands-on labs, which provided broad exposure to Azure’s ecosystem. This was great for educating myself on all of the different services and technologies available to use. After these labs were finished, I would often stick around and fidget with things just to see how expansive the functionality was.
For the actual exam itself, by far the best resource was questions from previous versions of the exam that were posted online. These questions got me acclimated with the exam subject matter, and thus what I needed to focus my studying on. Many questions followed a pattern of hyperfocusing on one specific aspect of the technology, and not the technology more broadly. For example, Azure stream analytics has this thing called “windowing functions” that allow you to peak into a specific frame of your streamed data to aggregate for analysis. I think this appeared at least five times on the exam, despite being a rarely used feature in practice.

One of my complaints for the exam is that there were many questions at best poorly worded, or at worst purposely misleading. The online forums I browsed came with intense debate by users in the comments trying to determine what the correct answer was. An example of this is certain scenarios requiring you to choose the "best" solution among multiple viable options, making some questions frustratingly subjective. A few questions like this came up in my exam and I had to cross my fingers.
What Getting this Cert Means
Earning this certication was about proving to myself that I could design and build real-world solutions in the cloud. Azure provides a platform for engineering modern solutions for today’s issues, and now I feel confident working with its capabilities to ensure that. Though my core expertise is in Python and SQL, cloud platforms like Azure enhance my understanding of scalable architectures. I see now that companies wanting to host their backend on a cloud platform like Azure have a surprising amount to choose from to expand functionality and really build out a competent architecture.
Engineering on the Cloud is not that bad
When you ask folks in Data Engineering circles what their thoughts on proprietary tooling is, you will overwhelmingly receive a negative response. There’s a skepticism that most problems can be solved by open-source tools (SQL, Python, Spark, Airflow) and that proprieary tools needlessly complicate the process. Once I got my hands dirty creating solutions in Azure based on various use cases, I realized that the options provided are both impressive and intuitive. It’s almost like this platform was built by actual engineers, go figure.
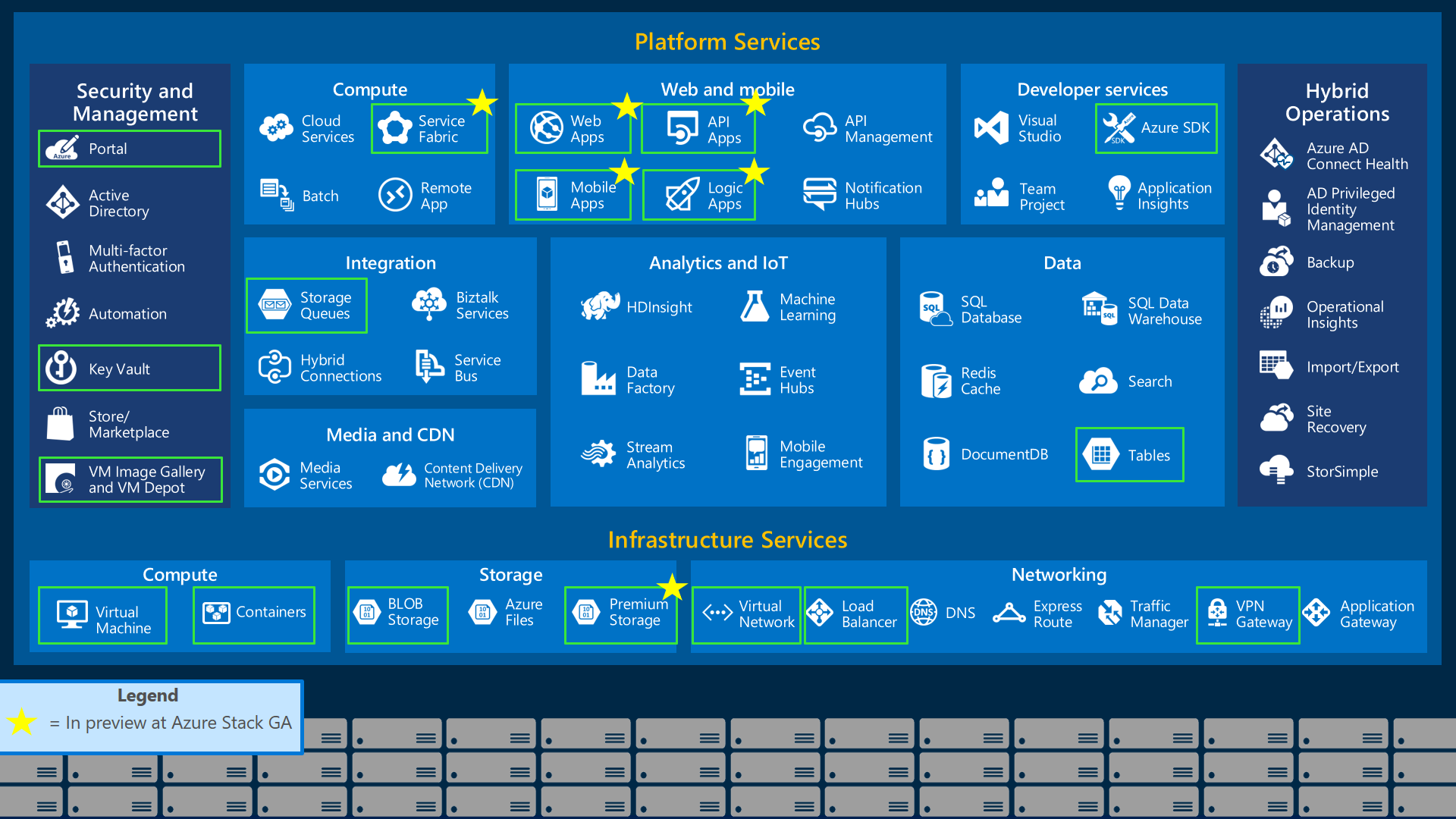
For example, Data Factory is a service on Azure that’s criticised for being a low-code tool not flexible enought for most situations requireing complex data delivery and transformation. It’s a service that accomplishes what a simple script could do, but with much more overhead. I think the confusion comes from a misunderstanding of what it does best: simple and repeatable operations that are developed quickly. If used correctly, its one of the more valueable assets as your disposal.
Databricks is Awesome
Azure provides a lot of different services and tools to build your data architecture, but none of it stands up to the Databricks integration. Even though Databricks is a competitor of Microsoft’s in the cloud computing space, the two have formed a strategic partnership to expose consumers to Databrick’s big data analytics platform while vastly expanding Azure’s appeal.
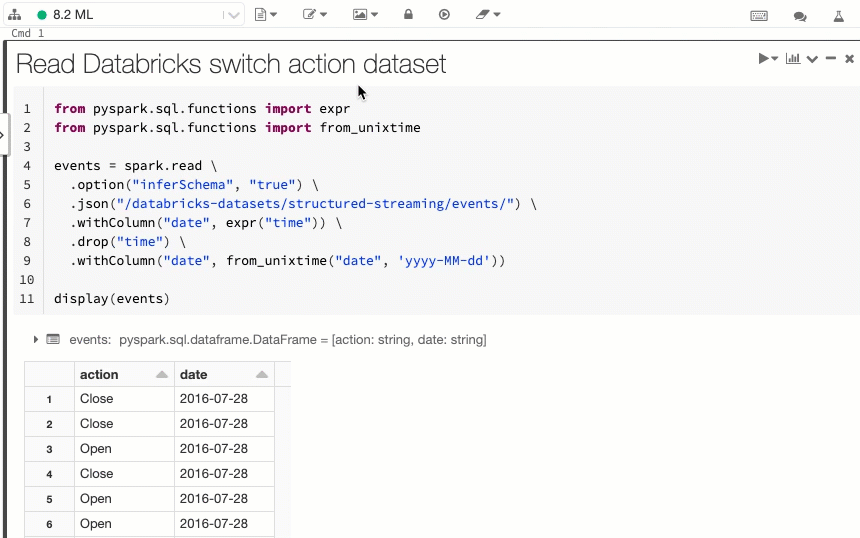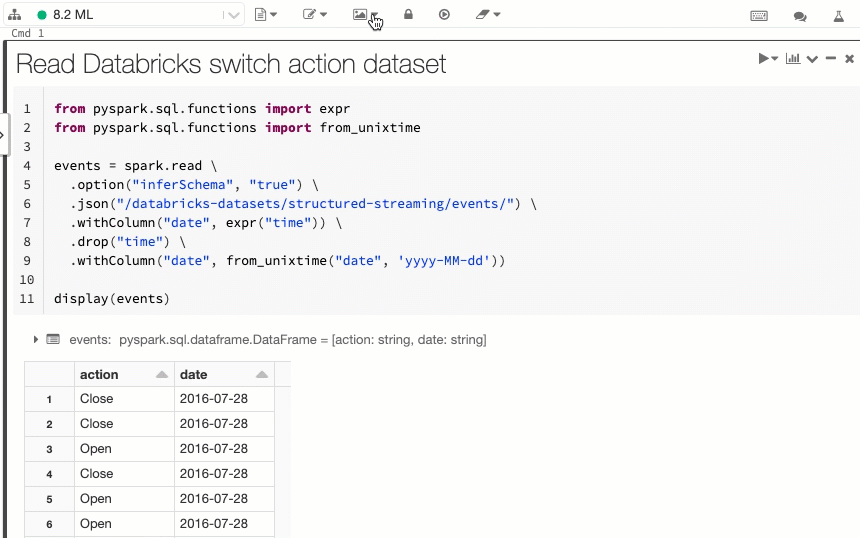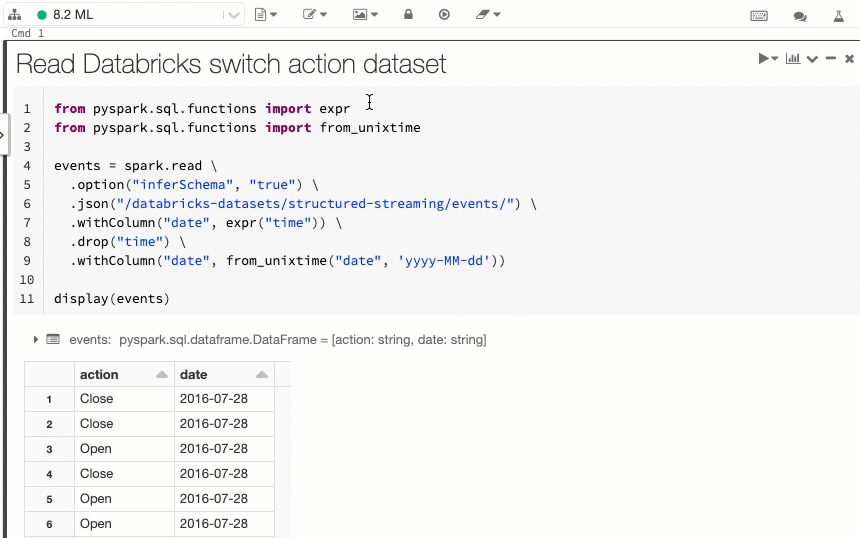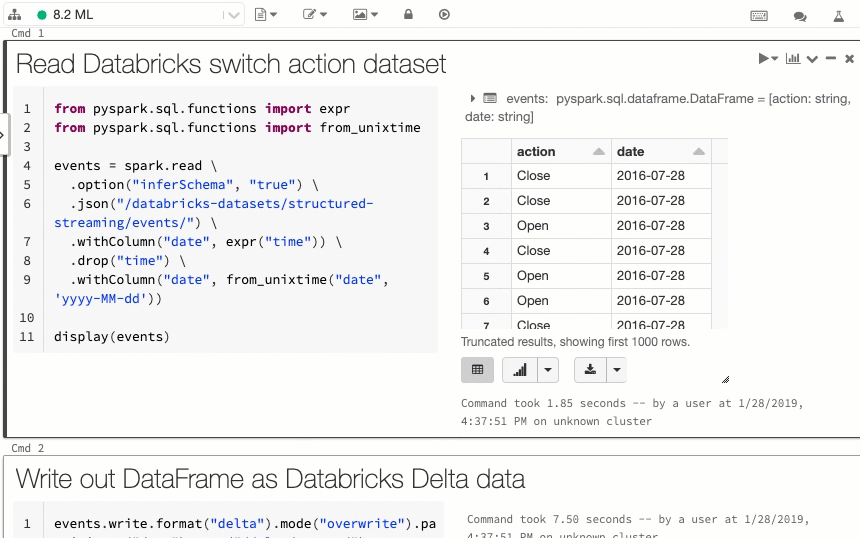
Databricks is built on Apache Spark, an open-source distributed processing framework for big data, machine learning, and real-time analytics. It seamlessly integrates with the entire Azure ecosystem, which makes ingestion, transformation, and analytics a lot easier. It leverages distributed processing on autoscaling clusters, so you don’t need to manually allocate resources. The range that this service has makes using the word “all purpose” feel like an understatement.
By far the most useful asset in the ecosystem, I started to ask the question of why anyone would use anything else. The only downside was the cost, which explains why it’s seen as a luxery option reserved for larger enterprises with large datasets. It is the reason I ended up blowing through all of my learner credits in my Azure free-trial account.
Learning is Fun
This may seem silly, but it occured to me that I haven’t taken an exam since I graduated college. I forgot how much I enjoyed the educational experience that I’d been surrounded by pretty much my entire life. When I began this journey, cloud computing felt overwhelming with the sheer amount of services, acronyms, and moving parts. As I moved past the terminology and theory, everything began to click and I realized how much I enjoyed problem-solved. Experimentation is what science and engineering are all about, and this experience gave me the exact kind of sandbox necessary to do so. There is a surprising amount of creativity and imagination involved with designing software, and I undertand that now more than ever.
Lastly
If you're looking to get into cloud data engineering, I’d recommend Azure as it gives you the ability to grow as an engineer and understand a platform that many of today’s company’s have built their technical architecture on. While the ecosystem can seem overwhelming at first, starting with the fundamentals and gradually expanding your knowledge makes it manageable.
If you have any questions or comments, feel free to send a message on my LinkedIn or directly to my email.
Thanks for reading.